神经网络到卷积神经网络(CNN)
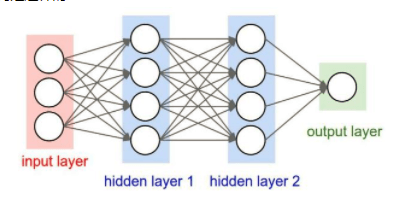
定义卷积层和池化
池化层夹在连续的卷积层中间,
用于压缩数据和参数的量,减小过拟合。
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding=’SAME’)
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding=’SAME’)
全连接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的
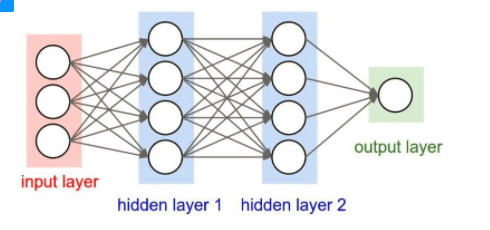
卷积神经网络之训练算法
1. 同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距。
2. 找到最小化损失函数的W和b, CNN中用的算法是SGD(随机梯度下降)。
卷积神经网络之优缺点
优点
• 共享卷积核,对高维数据处理无压力
• 无需手动选取特征,训练好权重,即得特征分类效果好
缺点
• 需要调参,需要大样本量,训练最好要GPU
• 物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型“)
卷积神经网络之典型CNN
• LeNet,这是最早用于数字识别的CNN
• AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比
• LeNet更深,用多层小卷积层叠加替换单大卷积层。
• ZF Net, 2013 ILSVRC比赛冠军
• GoogLeNet, 2014 ILSVRC比赛冠军
• VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
全部代码:
import tensorflow as tf
import numpy as np
sess=tf.InteractiveSession()
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding=’SAME’)
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding=’SAME’)
b=np.load(“D:\Documents\python tes/0001.npy”)
a=np.load(“D:\Documents\python tes/0002.npy”)
a=tuple(a)
b=tuple(b)
x=tf.placeholder(tf.float32,[None,315], name=”x”)
y_=tf.placeholder(tf.float32,[None,3], name=”y_”)
x_img=tf.reshape(x,[-1,3,105,1], name=”x_img”)
w_conv1=tf.Variable(tf.truncated_normal([3,3,1,32],stddev=0.1), name=”w_conv1″)
b_conv1=tf.Variable(tf.constant(0.1,shape=[32]), name=”b_conv1″)
h_conv1=tf.nn.relu(conv2d(x_img,w_conv1)+b_conv1)
h_pool1=max_pool_2x2(h_conv1)
w_conv2=tf.Variable(tf.truncated_normal([3,3,32,50],stddev=0.1), name=”w_conv2″)
b_conv2=tf.Variable(tf.constant(0.1,shape=[50]), name=”b_conv2″)
h_conv2=tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2)
h_pool2=max_pool_2x2(h_conv2)
w_fc1=tf.Variable(tf.truncated_normal([27000,1024],stddev=0.1), name=”w_fc1″)
b_fc1=tf.Variable(tf.constant(0.1,shape=[1024]), name=”b_fc1″)
h_pool2_flat=tf.reshape(h_pool2,[-1,27000])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1)
keep_prob=tf.placeholder(tf.float32, name=”keep_prob”)
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
w_fc2=tf.Variable(tf.truncated_normal([1024,3],stddev=0.1), name=”w_fc2″)
b_fc2=tf.Variable(tf.constant(0.1,shape=[3]), name=”b_fc2″)
y_out=tf.nn.softmax(tf.matmul(h_fc1_drop,w_fc2)+b_fc2,name=”y_out”)
loss=tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y_out),reduction_indices=[1]),name=”loss”)
train_step=tf.train.AdamOptimizer(1e-3,name=”train_step”).minimize(loss)
correct_prediction=tf.equal(tf.argmax(y_out,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name=”accuracy”)
tf.global_variables_initializer().run()
saver=tf.train.Saver(max_to_keep=1)
with tf.device(‘/gpu:0’):
for i in range(50000):
if i%100==0:
train_accuracy=accuracy.eval(feed_dict={x:b,y_:a,keep_prob:0.11})
print (“step %d,train_accuracy= %g”%(i,train_accuracy))
train_step.run(feed_dict={x:b,y_:a,keep_prob:0.5})
